
Info Tech Nearly 10 years ago, Intel formally unveiled the new design and manufacturing process it would use for its microprocessors. Before 2007, there was no exact, predictable alignment between the deployment of new manufacturing techniques at smaller process nodes and the debut of new architectures. From 2007 forward, Intel followed a distinct cadence: New process nodes would be designated as “ticks,” and new architectures built on the same process node would be called “tocks.”

This approach ensured Intel was never attempting to build a brand-new CPU architecture at the same time it ramped a new process node, and gave the company almost a decade of steady (if slowing) progress. That era is over.
In its recent 10-K filing, Intel stated the following:
As part of our R&D efforts, we plan to introduce a new Intel Core microarchitecture for desktops, notebooks (including Ultrabook devices and 2 in 1 systems), and Intel Xeon processors on a regular cadence. We expect to lengthen the amount of time we will utilize our 14nm and our next generation 10nm process technologies, further optimizing our products and process technologies while meeting the yearly market cadence for product introductions.
The company also released an image to show the difference between the old tick-tock model and the new system:
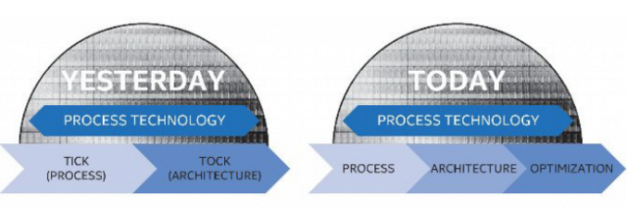
Intel goes on to state that it intends to introduce multiple product families at future nodes, with advances integrated into those architectures in ways that aren’t communicated by node transitions.
We also plan to introduce a third 14nm product, code-named “Kaby Lake.” This product will have key performance enhancements as compared to our 6th generation Intel Core processor family. We are also developing 10nm manufacturing process technology, our next-generation process technology.We have continued expanding on the advances anticipated by Moore’s Law by bringing new capabilities into silicon and producing new products optimized for a wider variety of applications. We expect these advances will result in a significant reduction in transistor leakage, lower active power, and an increase in transistor density to enable more smaller form factors, such as powerful, feature-rich phones and tablets with a longer battery life.
In other words, Intel believes it can offer improvements in different areas that correspond to better user experiences — and it may be right.
The evidence of iteration
In recent years, ARM, AMD, and Nvidia have all introduced architectural improvements that substantially improved on power consumption and performance despite being built on the same node.
In AMD’s case, Carrizo offers substantially better CPU and GPU performance at low TDP compared to the Kaveri APU it replaces. While it’s true that AMD’s APUs often aren’t shown or priced to best effect by OEM system designs, Carrizo is a notable improvement over AMD’s previous offerings. Part of this is likely due to AMD’s decision to use Adaptive Voltage and Frequency Scaling instead of the Dynamic Voltage and Frequency Scaling that Intel (and AMD, historically) have both relied on. More information on AFVS vs. DFVScan be found here, if you’re curious on the technical approach and why AMD adopted it.
ARM tends to be a bit more closemouthed than Intel when it comes to aspects of CPU design, but its own public slides show how Cortex-A9 performance evolved over time.

ARM claims that its architectural enhancements to the Cortex-A9 improved its per-clock performance by nearly 50%, over and above any frequency enhancements. When combined with improvements via process node and CPU clock, the final chip was nearly 3x faster than the first models that debuted on 40nm.
Finally, there’s Nvidia. While we hesitate to draw too much from GPU manufacturing, given the vast differences between CPU and GPU architectures, Nvidia’s Maxwell was ahuge leap forward in performance-per-watt over and above what Kepler offered. The end result was higher frame rates and a more efficient architecture, all while staying on TSMC’s mature 28nm process.
Each of these companies took a different route to improving power efficiency. AMD introduced new types of power gating and binning while simultaneously makingarchitectural improvements. ARM took an iterative approach to fixing performance-sapping issues without declaring the later revisions of the Cortex-A9 to be different processors. Nvidia built a new architecture on an existing, mature node, blending some approaches it had used with Fermi with its existing Kepler architecture, then adding better color compression and other enhancements to the GPU stack.
Intel’s 10-K goes on to mention other long-term investments the company is making into EUV, and the firm has previously discussed how it sees a path forward to 10nm and below without relying on the next-generation lithography system. The firm isn’t giving up on process node scaling, it’s just not going to try to hit the same cadence that it used to.
The counter-argument
There is, however, a counter-argument to the optimistic scenario I just laid out. Unlike AMD or ARM, Intel’s x86 processor designs are extremely mature and highly optimized. Carrizo may introduce some innovative power management techniques, but AMD had to find a way to take Bulldozer — an architecture designed for high clock speeds and high TDPs — and stuff it into a 15W power envelope. The company’s engineers deserve a month in Tahiti for managing that feat at all, but it’s no surprise it took the firm multiple iterations on the same process node to do it. ARM’s Cortex-A9 was a fabulous mobile processor in its day, but it was also arguably ARM’s first stab at a laptop/desktop-capable CPU core. There was going to be low-hanging fruit to fix, and ARM, to its credit, fixed it.
Nvidia’s Maxwell GPU might demonstrate the performance and efficiency gains of advances to one’s graphics architecture, but Intel has actually made some significant strides in this area already. Modern GPU designs also aren’t as mature as their CPU counterparts — Intel has been building out-of-order CPUs since the Pentium Pro in 1995; the first programmable GPU debuted in the Xbox 360 in 2005 (AMD) or Nvidia’s G80 (2006) depending on how you want to count.
This view would argue that the modest clock-for-clock performance improvements to Haswell and Skylake over their predecessors reflects neither laziness nor market abuse, but a more fundamental truth: Intel is currently building the best, most power-optimized processor it knows how to build, with no near-term amazing technology other than process improvements to push the envelope farther.
Whichever view is more precise, it’s not particularly surprising to see Tick-Tock passing into history. As we’ve covered at length over the past few years, it’s getting harder and harder to hit new node targets, and Intel typically sets density and gate length requirements that are harder to hit than its competitors. Even now, Intel’s 14nm node is more dense than the hybrid 14/20nm approach offered by Samsung and TSMC; TSMC’s 10nm node in 2017 is expected to hit the same densities Intel achieved in 2015. The question is, does leading the industry in such metrics actually give Intel enough of an advantage to justify the cost?
Intel’s decision to transition away from the tick-tock model is a tacit recognition that the future of semiconductors and their continued evolution is considerably murkier than it used to be. The company is retrenching around a more conservative model of future progress and betting it can find complementary technologies and approaches to continue to deliver steady improvement. Given the time lag in semiconductor design, it’ll be a year or two before we know if this approach worked.
Fortunately, tick-tock continues to work beautifully in rather different contexts.